
前回は「トランザクションについて」というテーマで、DB操作する際のトランザクション処理について、説明をしてきました。
今回は「データベースの正規化」というテーマになります。
データベースの正規化はデータベース設計の際に必要な考え方になります。
目次
正規化とは?
データベースの正規化とは、データベースを設計する際に、テーブルの冗長性を排除して扱いやすい形にすることです。
もう少し簡単に説明すると
「無駄なく、分かりやすく、簡単に扱えるように設計されたデータベース」のことを、正規化されたデータベースといいます。
例えば・・・
以下のように、社員マスタと部署マスタがあるとします。この2つのテーブルは正規化されていると言えるでしょうか?
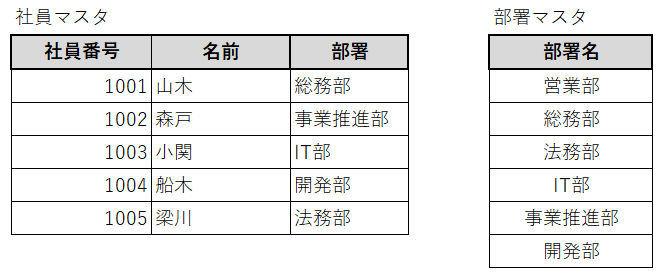
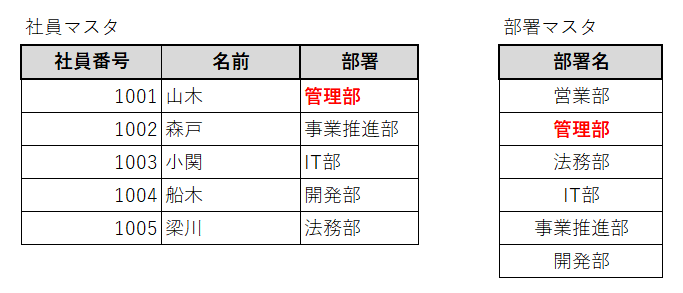
例えば、総務部という部署の名前が「管理部」という名前の部署になったとき、社員マスタと部署マスタの両方を更新しなければなりません。
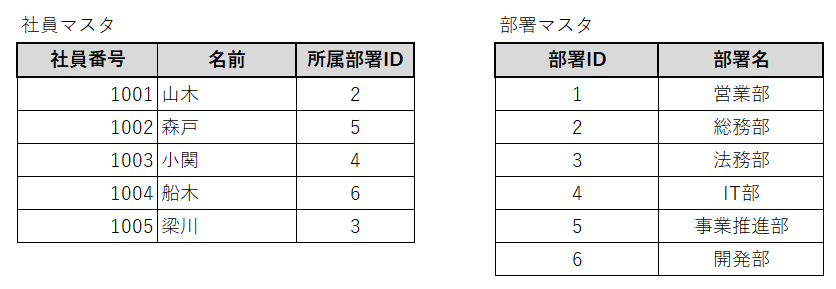
しかし、社員マスタと部署マスタを以下のように設計していれば、修正するのは部署マスタだけで済みます。
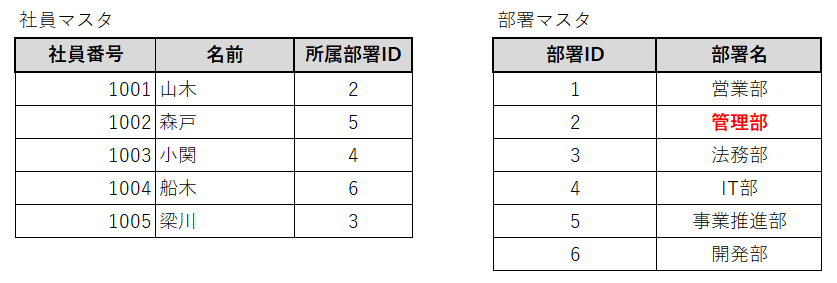
これが正規化されているデータベース設計の一例になります。
このように、データベースを正規化して設計しておくことで、保守性の面でメリットがあることが分かると思います。
※ここに挙げた例は厳密にいえば正規化の操作とは少し異なります。あくまで、データベース設計は使いやすさを重視して考える余地があるということをまずは分かってもらえればと思います😄
正規化の種類
正規化されたデータベースはいくつかの種類に分けられます。
| 正規化の種類 | 説明 |
|---|---|
| 非正規形 | テーブルに繰り返しグループが存在する |
| 第一正規形 | 非正規形から繰り返しグループを排除したもの |
| 第二正規形 | 第一正規形から部分関数従属を排除したもの |
| 第三正規形 | 第二正規形から推移関数従属を排除したもの |
| ボイスコッド正規形 | 主キー以外のカラムが全て主キーに完全関数従属 |
| 第四正規形 | ボイスコッド正規形から多値従属性を排除したもの |
| 第五正規形 | 候補キーの中で結合従属性を充足するようにしたもの |
一般的に、第三正規形までを満たしていることを「正規化されている」といいます。
※第五正規形まだ満たすテーブル設計を目指すのも悪くないですが、運用の利便性から敢えて部分的に非正規形のテーブル設計をすることもあり、現実的には第三正規形までを意識して設計するのが程よいことが多いです。
非正規形
以下のようなジャニーズのグループデータを例に説明する。
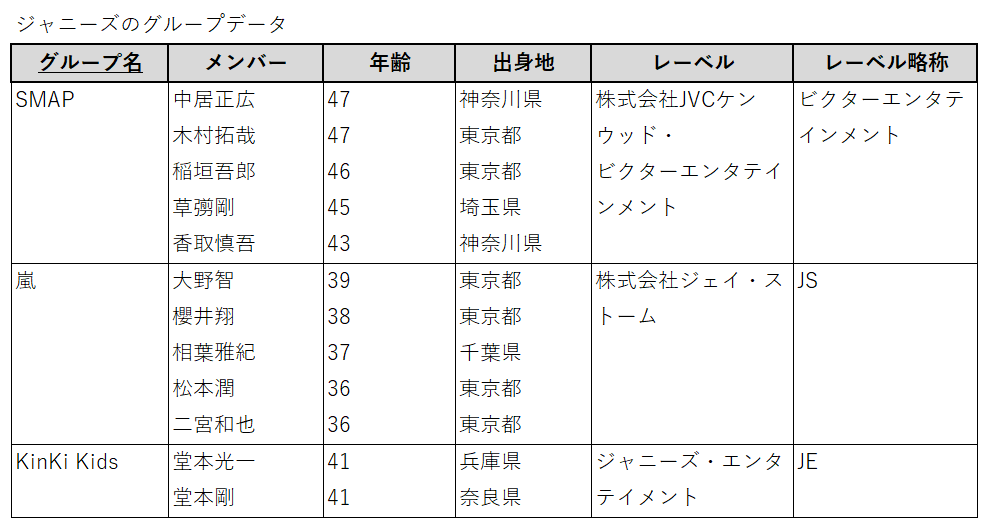
このテーブルのキーは「グループ名」
キーとは、その値が決まれば、どのレコードか特定することが出来る値のことを言います。SMAPなら1行目、嵐なら2行目、KinKi Kidsなら3行目、といったイメージです。
さて、このテーブルには1行の中に複数のデータが含まれています。
SMAPの行の「メンバー」の列に5人分のデータが入っていますよね。このような状態を「繰り返しグループ」と呼びます。
繰り返しグループのあるテーブルは「非正規形」のテーブルとなります。
第一正規形
正規化の種類で説明したように、非正規形から繰り返しグループを排除したものが「第一正規形」になります。
第一正規形は必ず1レコードに1つずつの値が格納されている状態です。
先ほどの非正規形データを第一正規形に修正すると以下のようになります。
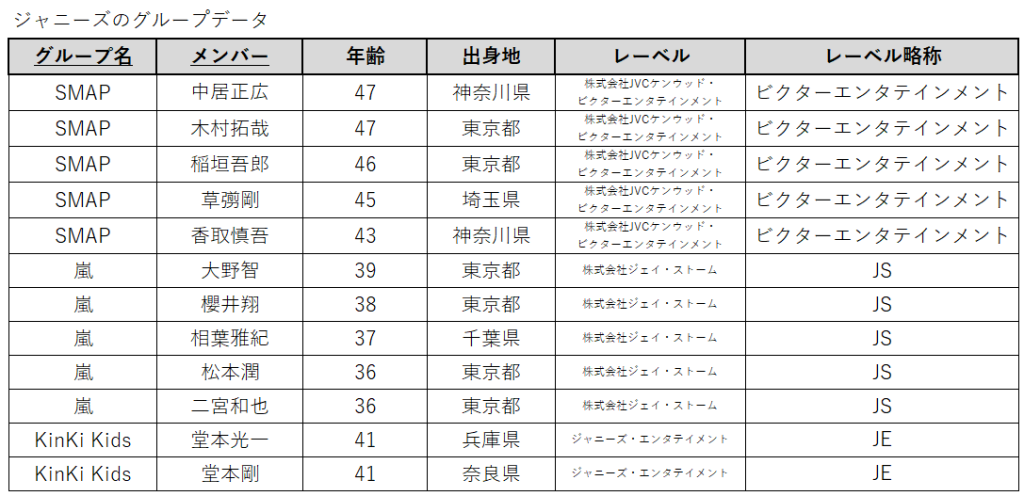
元々は主キーが「グループ名」だけでしたが、主キーはそれが決まればどのレコードかが確定するカラムでなければならないので、グループ名だけでは確定しなくなってしまいます。
そこで、修正後の第一正規形のテーブルでは「グループ名」と「メンバー」の2つを合わせて主キーとすることにします。
このように複数のカラムで主キーを構成しているキーを「複合キー」と呼びます。
さて、ここで「メンバー」と「年齢」・「出身地」に注目してみてください。
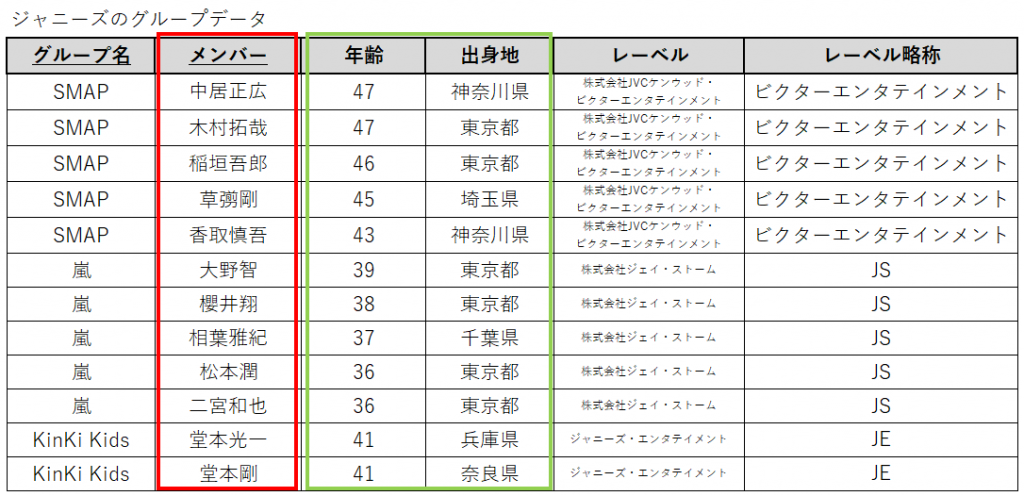
「メンバー」が決まれば、そのメンバーの年齢も出身地も一意に決まることが分かると思います。当たり前ですよね、年齢とか出身地って、そういうものなので。
このように、キーではない属性が、キーの一部によって一意に決まる状態のことを部分関数従属といいます。

第二正規形
第一正規形から上記の部分関数従属を取り除いたものを「第二正規形」と呼びます。
先ほどの第一正規形のデータを第二正規形に修正すると以下のようになります。
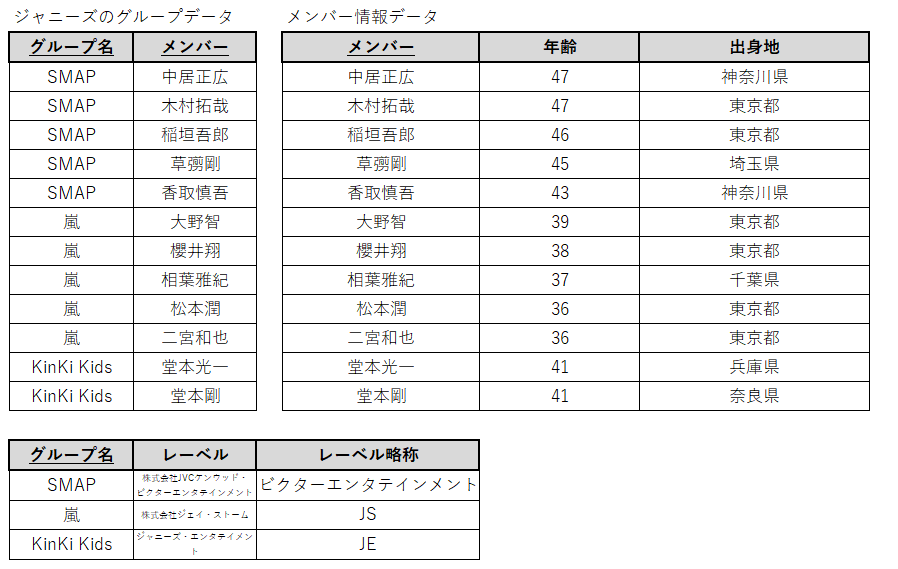
「メンバー」と「年齢」・「出身地」
「グループ名」と「レーベル」・「レーベル略称」
が部分関数従属していたので、これを別のテーブルに分けることによってそれを除外しました。
これで第二正規形の出来上がりです。
さて、続いて「レーベル」と「レーベル略称」の組み合わせを見てみてください。

どちらもキーではない属性ですが、「レーベル」が決まれば「レーベル略称」も一意に決まります。
このように非キー属性間で関数従属していることを「推移関数従属」と呼びます。
第三正規形
第二正規形から推移関数従属を排除したものを「第三正規形」と呼びます。
先ほどの第二正規形を修正して第三正規形を作ってみます。
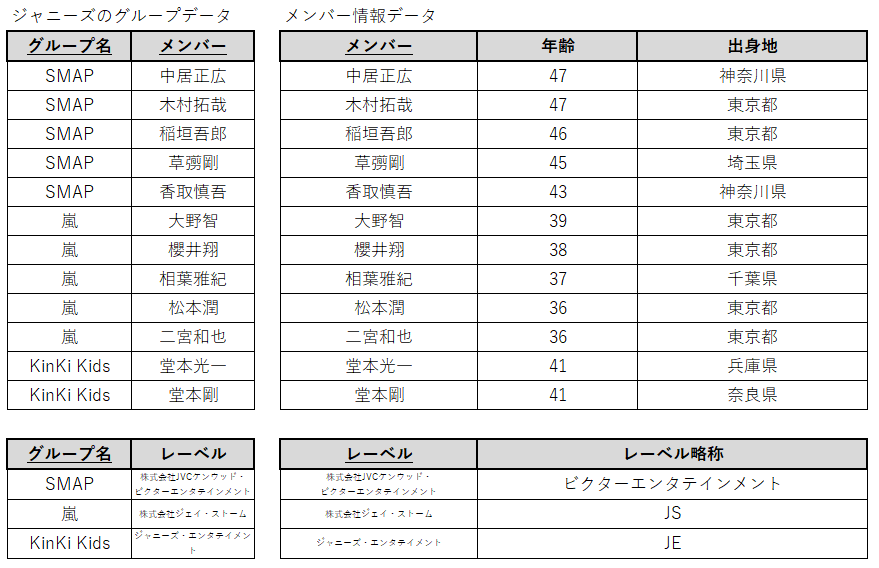
これで推移関数従属が無くなりました。
この形を第三正規形と言います。そして一般的にはここまで整理された状態で「正規化された」と言うことができます。
もう少し良くしたい?
一応これで正規化されたと言えなくないのですが、1つ改善したい点があります。それは各テーブルのキー値です。
例えば、レーベルの名称が改称された場合、2つのテーブルのデータを修正する必要があります。これは保守性に乏しいデータベース設計となります。
その点を考慮して、修正すると以下のようになります。
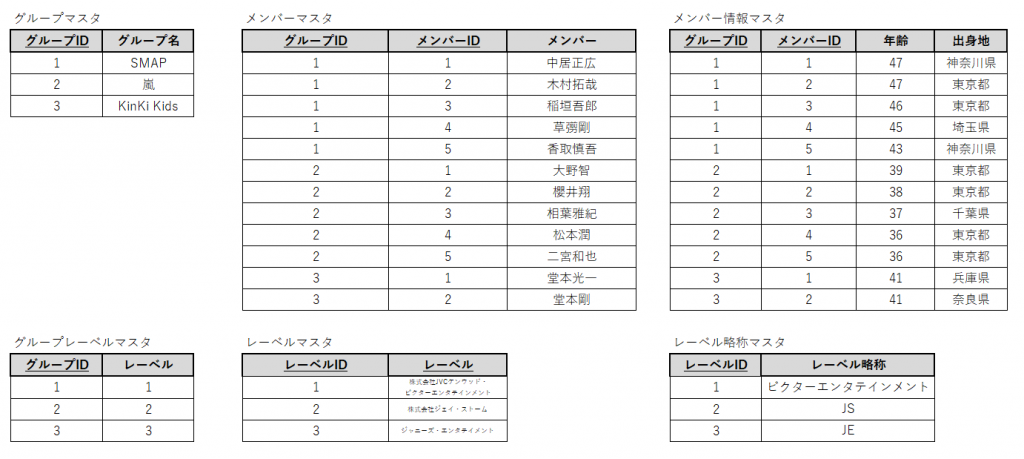
このように、各テーブルのキーだったものをIDとして番号を振り、その番号を新しくそのテーブルのキーとしました。そうすると、メンバーの名前やレーベル名をテーブル間で使いまわすことが無くなるので、データの補正はしやすくなります。
が、果たしてこれが正解の形でしょうか・・・?
実は、テーブル設計に正解はありません。
そのシステムの使い方、シチュエーションに合わせて、何を重要視するかを考えて、最適な設計を行うことが重要です。
例えば、システムの運用上、手動で補正することは少ないが、テーブルの値を見ることが多いとなれば、IDに変換したテーブルよりも、その前の状態の方が明らかに適していると言えるでしょう。
まとめ~正規化するメリットとデメリット
メリット
・データの管理が容易になる
→手動運用での補正が楽になることが多い
・データの共通性
→標準化された考え方のもと正規化されていれば、他のシステムから参照しやすい
・データ容量の削減
→無駄なデータを保持しないので、データ容量が多くなり過ぎずに済む
デメリット
・テーブルが増える
→テーブルが増えることにより検索が難しくなったり、クエリが複雑になることでパフォーマンスが低下することになる。
練習問題
問題
次のテーブルを第三正規形に修正せよ

答え
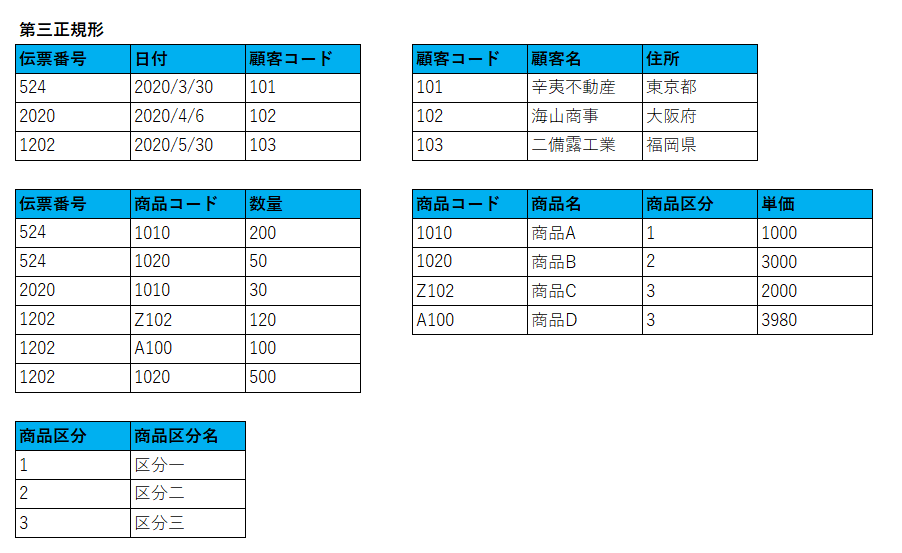










最近のコメント