
この記事は「SQLをこれから勉強する初心者向け」の記事になります。
全8回に渡ってSQLの勉強をしていきます。
途中に練習問題も挟んでいきますので、最後まで到達すればもうあなたはSQL初心者脱却です!
第1回は、サラッと軽く「データベース」についての説明をします。
データベースの概要
データベースとは・・・
あるテーマに沿ったデータを集めて管理し、簡単に検索や抽出をできるようにしたもの。
データベースをコンピュータ上で管理するためのシステムを「データベース管理システム(Database Management System, DBMS)」と言います。
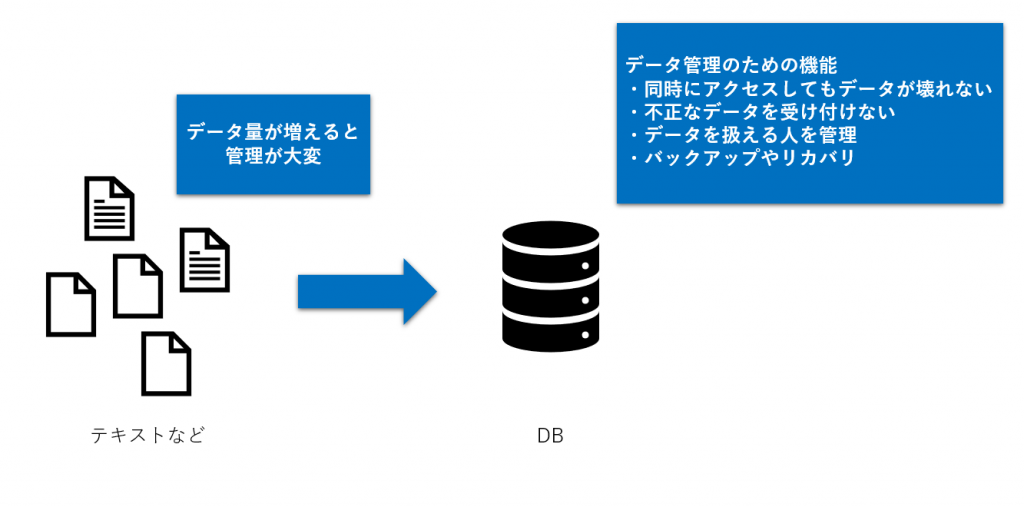
データモデル
データベースは、通常以下の流れで設計/構築する

概念データモデル
データベースを設計する際は、概念データモデルの作成から行います。
概念データモデルを描く際は、「ER図(ERD:entity-relationship diagram)」を用いることが多いです。
概念データモデルを作成するステップは主に以下の2ステップになります
1.エンティティの抽出
2.リレーションシップの設定
まずは、1つ概念データモデルの例を見てもらいましょう。
例えば、学校の先生が「生徒のテストの成績」を管理するためのデータベースを作成したいとします。この場合、以下のような概念データモデルになります。
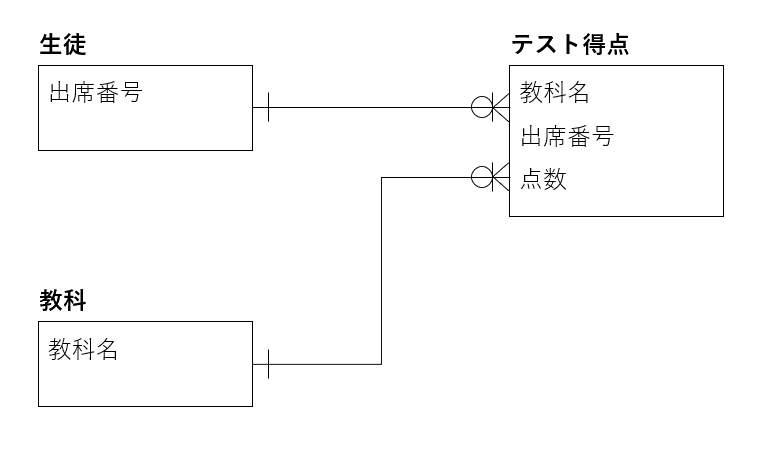
テストの点数を管理したいので、重要なのは
「誰がどの教科で何点取ったか」です。
その「誰」「教科」「何点」という3つのポイントを、図のように箱に書き出して、それぞれ「生徒」「教科」「テスト得点」と名付けます。
この箱に書きだしたそれぞれの物のことを「エンティティ」と呼びます。
必要なエンティティを書きだす作業がステップ1の「エンティティの抽出」です。
そして、それぞれのエンティティが線で繋がっていますが
この繋がりのことを「リレーションシップ」と呼びます。
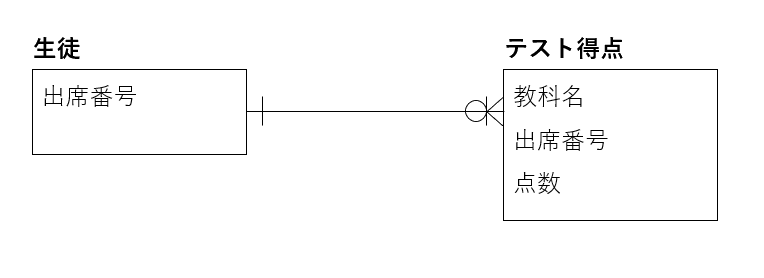
例として「生徒」と「得点」のリレーションシップを見てみましょう。
線で繋がっているのは、各エンティティには意味的な繋がりがあると言うことです。(先に挙げた例では、生徒と教科は繋がっていません。これは直接的にはつながりが無いからです。)
そして、線の先の棒の数や〇は「繋がり方」を表します。つまり「1:1」なのか、「1:多」なのか、あるいはデータが無い場合があるのか、ということを表しています。
| 記号 | 意味 |
|---|---|
| 〇 | 0(データが無い場合がある) |
| | | 1 |
| 鳥足(3本に広がる線) | 多 |
生徒1人に対して、テストは複数教科、あるいは複数回行われるので、このエンティティは「1:多」の関係になります。
また、まだテストが1回も行われていない場合があるかもしれないので、〇印が「テスト得点」側に付いています。
逆に、テストが対象の生徒に行われていて、生徒がいないということはあり得ないので、「生徒」側には〇印がありません。
このようにして、登場してくる全てのエンティティを書きだし、そのリレーションシップを表現するのが、 ER図を使った概念データモデルの設計になります。
論理データモデル
論理データモデルは、概念データモデルのパワーアップバージョンみたいなものです。
概念データモデルに対して、必要になる項目を整理して追加します。
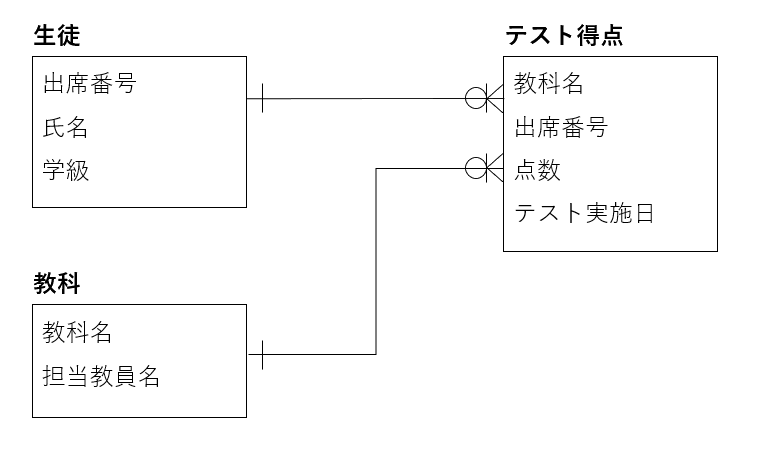
例えば、先ほどの概念データモデルの「テスト得点」に対して、論理データモデル設計として”テスト実施日“を追加しました。
これは、同じ教科、同じ生徒に対するテストでも、違う日に行われた別のテストで同じ点数を取ることもあるため、その見分けを付けるために必要な項目になります。
論理データモデル設計では、このように項目の整理や、不要なエンティティが無いか、不足しているエンティティが無いかを整理します。ここで「データベースの正規化」という作業を行うのですが、詳細は第7回で説明します。
また、概念データモデル設計と論理データモデル設計は実施する内容が近いために、実務では同時に行うことが多いです。
物理データモデル
論理データモデル設計でER図が完成したら、物理データモデル設計に移ります。
具体的には、それぞれのエンティティの名前、項目の名前、項目の型や長さの定義などを決定します。
少々細かい内容になってしまうので、第1回の今回では割愛とします。
代表的なRDBMSの種類と特徴
DBの中でも、各エンティティにリレーションシップを持たせたデータの保持方式をさせるDBのことを「RDB:Relational Database」と呼びます。
RDBを扱える代表的なManagement Sysmtem(RDBMS)について紹介します。
| RDBMS名 | 説明・特徴 |
|---|---|
| Microsoft SQL Server | ・Transact-SQLというSQL Server向けに拡張されたSQLを使用している。 ・OLAP、多次元解析などのビジネスインテリジェンスやデータマイニングのための機能を備えている。 ・データベースの自動圧縮機能を備えている。ただし圧縮処理の最中はパフォーマンスが著しく低下し、また圧縮中にハード障害が起きるとデータベースファイルが破壊される可能性が高いため、デフォルトでは自動圧縮はOFFとなっている。 ・GUIツール類が充実しており、DBMSに不慣れなユーザーでも扱いやすい 高機能、多機能、GUIツール類が充実 |
| Oracle | ・行レベルロック ページ単位ではなく処理対象の行のみにロックをかけることにより、待ち時間の発生確率を低減している。 また、ロックされた行に対する参照は可能であるため、処理待ちが発生しない。 ・読み取り一貫性 SELECTを発行した時点のデータが読み取れることを保障する機能。更新前のデータが格納されているUNDOセグメントを参照することで、排他ロックによるブロックを受けずにデータを読み取ることができる。 ・移植性 データベースエンジン・コアAPI周りは全てC言語、各種ツール類はほとんどがC言語またはJavaで記述されており、広いプラットフォームでの移植性をもつ。ユーザーの開発する応用プログラムも、C言語、C++、COBOL、JavaまたはWindowsではODBC等の規格に対応し移植性は良い。 高機能、広いプラットフォーム移植性 |
| MySQL | MySQLは、オラクルが開発するRDBMSの実装の1つ。オープンソースで開発されており、GNU APLと商用ライセンスのデュアルライセンスとなっている。 他の多くのオープンソースプロジェクトと異なり、スウェーデンの単一の営利企業「MySQL AB」によって保持されていた。2008年2月26日にMySQL ABがサン・マイクロシステムズに買収されたことによってサン・マイクロシステムズの所有となった。その後サン・マイクロシステムズはオラ靴に買収され、オラクルの所有となった。 オープンソースで小・中規模システムであれば十分な機能 |
| PostgreSQL | PostgreSQL(ポストグレスキューエル、通称ポスグレ)は、BSDライセンスに類似するライセンスにより配布されているオープンソースのオブジェクト関係データベース管理システムである。 オープンソース |
第1回「データベースとは」は以上になります。
次回、第2回は「テーブルの作成」というテーマになります。









最近のコメント